
ClickHouse In the Storm. Part 2: Maximum QPS for key-value lookups
上一篇文章调查了ClickHouse的连接性基准,以估计服务器并发的总体性能。 在本文中,我们将以实际示例为例,并在涉及实际数据时探讨并发性能。
MergeTree: Key-value lookup
让我们看看MergeTree引擎表如何处理高并发性,以及它能够处理多少个QPS用于键值查找。
我们将使用2个综合数据集:
‘fs12M’-具有1200万条记录的表,id为FixedString(16)和5个不同类型的参数:
1 | CREATE TABLE default.fs12M ( |
‘int20M’-具有2000万条记录的表,id为UInt64和一个Float32参数:
1 | CREATE TABLE default.int20M ( |
You can find the create table statements here.
我们将在下面使用两个查询来检查在4种情况下对这些表的lookup查询性能:
- 通过id查询单条记录
- 以1:3 hit/miss比率查询100条随机记录
- 此外,还要为上面的每个测试检查两种形式的ClickHouse过滤——WHERE和PREWHERE (PREWHERE子句与WHERE语法相同,但内部工作方式略有不同)。
1 | SELECT * FROM table WHERE id = … |
You can find all the select statements here.
CHOOSING INDEX_GRANULARITY
MergeTree的最重要参数之一是index_granularity。 让我们尝试为每种情况找到最佳的index_granularity:

由于上面的表总结了几个不同测试的结果,所以该图显示了规范化到最佳运行的QPS(即1 =表示所有测试都给出了最大QPS)。如您所见,相比’int20M’, ‘fs12M’在index_granularity较小时性能较好, 因为键更大,涉及的列更多(包括一个相当大的字符串)。
- For fs12M the best QPS performance gives index_granularity 64 & 128
- For int20M - 128 & 256.
小查询的性能可以通过使用uncompressed cache提高. ClickHouse通常不缓存数据, 但是对于快速的简短查询, 可以使用internal cache来保存未压缩的数据库块. 可以使用配置文件级别的use_uncompressed_cache设置将其打开。 默认缓存大小为8GB,但可以增加。
目前use_uncompressed_cache参数在我们的生产环境没有打开, 我查阅了一些资料发现可能是参考了国内的博客, 而国内的博客可能都是互相
借鉴都没有自己看这个参数, 也可能是我臆测的use_uncompressed_cache默认0关闭, 但在文档中有如下描述
For queries that read at least a somewhat large volume of data (one million rows or more), the uncompressed cache is disabled automatically to save space for truly small queries. This means that you can keep the ‘use_uncompressed_cache’ setting always set to 1.
不过在本文结论在, 作者建议只对特定的查询和特定的用户开启use_uncompressed_cache, 但是use_uncompressed_cache其实好像无法针对查询开启但可以针对会话
Let’s see how QPS looks for 100 random ID lookups:
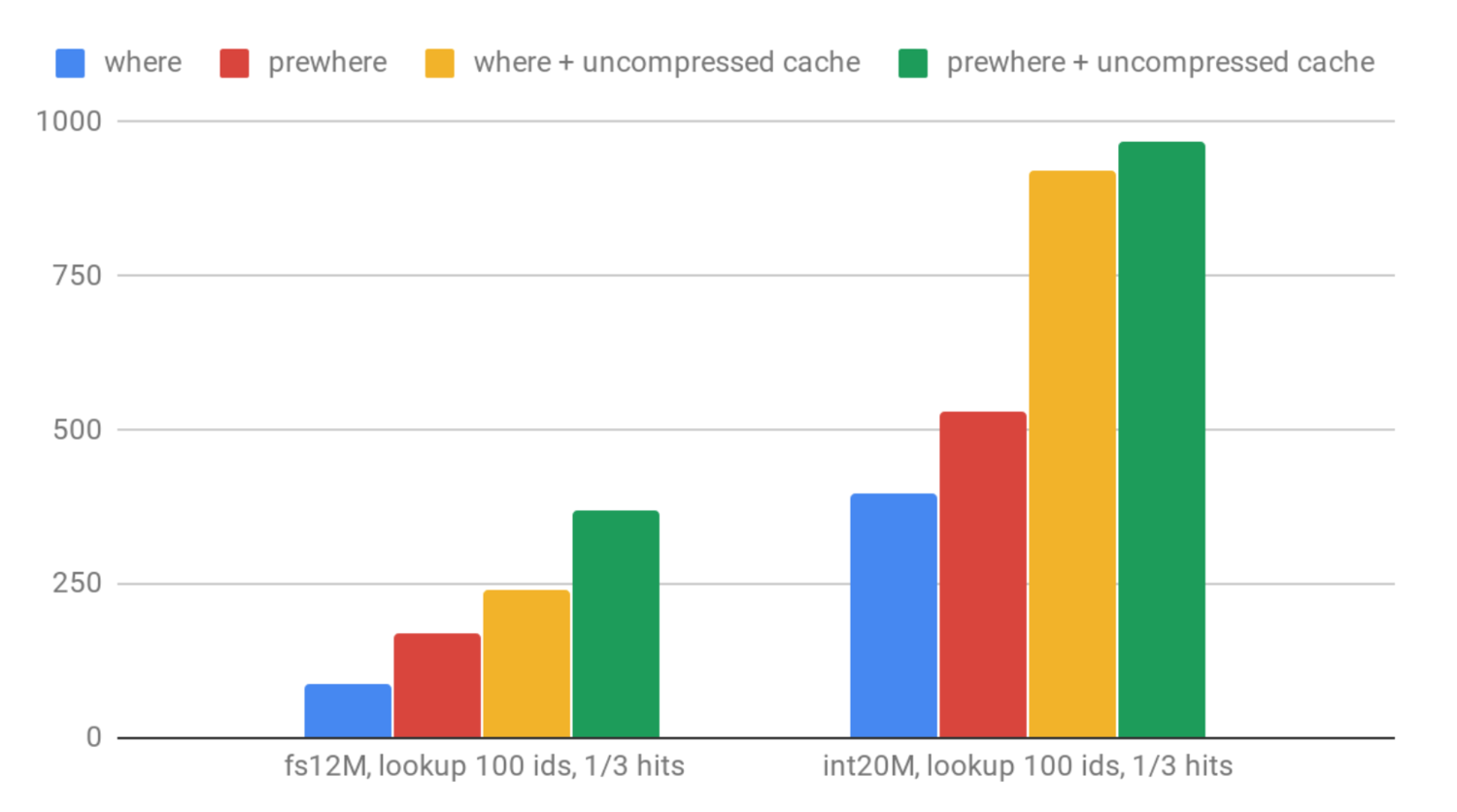
正如我们预期的那样,对’fs12’的查找要比对’int20M’的查找慢。 使用PREWHERE而不是WHERE可以显着改善性能。
Here are QPS numbers for single value lookup:

启用use_uncompressed_cache最多可提高50%性能。 对于’int20M’单点查询,它的效果似乎较低,因为在所有测试案例中,它的运行速度都非常快。
但是,如果该QPS还不够,该怎么办? ClickHouse可以做得更好吗? 可以,但是我们必须切换到其他数据结构以确保数据始终在内存中。 ClickHouse为此提供了多种选择:我们将尝试使用外部Dictionary和Join引擎。
Dictionary
通常使用字典来与外部数据集成。 请参阅有关此主题的博客文章。 但是,也可以使用字典来为已经存储在ClickHouse中的数据建立内存中的缓存。 让我们看看如何做。
首先,让我们为”int20M”表配置字典:
1 | <dictionaries> |
您可以从此处下载我们为您准备好文件,该文件需要放置在ClickHouse配置文件夹中。
不幸的是,目前无法使用FixedString键创建字典,因此我们仅测试’int20M’情况。
为了通过键获取值,我们可以使用字典get函数对其进行查询:
1 | select dictGetFloat32('test100M','value',9221669071414979782) |
You can find all the test selects here

好吧,它的QPS约为9.2K:比MergeTree更好.
根据经验对于single point select MySQL可以轻松达到90k qps. 这也说明ClickHouse并不是用来做高并发短查询的.
另一个选项是使用“缓存”字典布局(‘cached’ dictionaries layout),它提示ClickHouse只将部分行保存在内存中。如果您的缓存命中率很高,那么它可以很好地工作。
如果您不需要过于频繁地更新字典,则字典效果很好。 更新是异步的; 字典会定期检查源表,以确定是否需要刷新它。 有时可能不方便。 另一个不便之处是XML配置。 应该很快用字典DDL修复它,但是暂时我们必须坚持使用XML。
Join table Engine
ClickHouse内部使用联接表引擎来处理SQL联接。 但是您可以像这样显式创建一个表:
1 | CREATE TABLE fs12M ( |
然后可以像插入其他表一样插入该表。理想情况下,您可以用一个INSERT填充整个表,但是也可以用parts来完成(但是仍然需要足够大的parts,最好不要有太多的parts)。联接表在内存中持久存在(就像字典一样,但是以一种更紧凑的方式),并且也在磁盘上刷新。也就是说,它将在服务器重启后恢复。
无法直接查询Join table; 您始终需要将其用作联接的正确部分。 有两个选项可从联接表中提取数据。 第一个类似于使用joinGet函数的字典语法(它是由一个贡献者添加的,自18.6开始可用)。 或者,您可以进行真正的联接(例如,使用system.one表)。 我们将使用以下查询来测试这两种方法:
1 | SELECT joinGet('int20M', 'value', 9221669071414979782) as value |
Results, QPS:

当您需要为每次查找进行大量的joinGet调用时,对于’fs12M’来说,joinGet和实际联接之间的区别显而易见。 当您只需要调用一次时-没有区别。
与字典相比,Join表的性能稍差。 但是,由于它已经在数据库架构中,因此维护起来更容易。 与字典相比,联接使用的内存更少,您可以轻松添加新数据,等等。 不幸的是,无法进行更新。 (That would be too good. :))
让我们总结一下所有QPS结果并将其放在一张图表中:

Latencies (90th percentile)


Conclusions - 结论
在本文的过程中,我们已经研究了并发基础知识。这是您可以用于自己的应用程序的一些主要结论。
ClickHouse is not a key-value database (surprise! :) )
如果您需要在Clickhouse内部模拟键值查找方案-连接引擎和字典可提供最佳性能
如果每秒有很多查询,则禁用日志(或降低日志级别)可以提高性能
启用uncompressed cache有助于提高查询性能(对于“小的”查询仅返回几行)。最好仅针对特定查询和特定用户profile启用它
在高并发方案中使用max_thread = 1
尽量保持同时连接的数量足够少,以获得最大的QPS性能。具体数字当然取决于硬件。使用我们的低端机器进行测试,16-32范围内的连接显示了最好的QPS性能
对于UInt64键的键值类型场景,index_granularity= 256看起来是最好的选择,对于FixedString(16)键,也要考虑index_granularity= 128。然而默认index_granularity为8192
使用PREWHERE而不是WHERE进行点查找。
Summary - 总结
ClickHouse不是key-value stroe, 但是根据我们的结果证实ClickHouse在不同并发的高负载下表现稳定, 并且能够在MergeTree表上(当数据位于文件系统缓存中时)每秒提供约4K(每秒)的查询, 当使用Dictionary或Join engine是甚至可以达到10k(每秒). 当然,在更好的硬件上,您会有更好的数字.
这些结果远非键值数据库(例如Redis,在相同的硬件上可提供约125K QPS),但在某些情况下,即使这样的QPS速率也可以令人满意。 例如-通过复杂的OLAP计算在实时创建的数据中进行基于id的查找/通过id从物化视图中提取一些聚合等。并且,ClickHouse还可以水平和垂直缩放。
简单ping和普通select之间的QPS差异表明,未来的优化具有一定的潜力。另外,将ClickHouse与键值数据库结合起来,这样就可以在两个方向上与ClickHouse无缝合作,这个想法听起来很有前途。如果你关注ClickHouse的pull requests,你可能已经看到了一些与Cassandra和Redis的草案整合。
请继续关注,并订阅我们的博客!
原文链接:
https://www.altinity.com/blog/clickhouse-in-the-storm-part-2